
The analyses of data from relational databases (LOB) applications is not an easy . The normalized relational schema used for an LOB application can consist of hundreds of tables. It is difficult to discover where the data you need for a report is located.
In addition, LOB applications do not track data over time(they perform many DML operations), though many analyses depend on historical data.
A Data warehouse is a centralized data database for an enterprise that contains merged, cleansed, and historical data. The DW data is more better for reporting purposes . The logical design of schema of DW is called Star schema and snowflake schema which consists of Dimension and fact Tables.
The data in DW comes from LOB / relational database . The data which comes in DW is more cleansed ,transformed . OF course , while coming into DW , the data must have gone through some changes so we can get the refreshed data in DW . One way to refresh or let the new data come into DW is through the night job schedule . The report for newly or refreshed data can then be read .
The physical design for the DW is simpler than the relational database design as it contains less tables joins .
————————————————————————————————————————————-
CHAPTER 1 : Introduction to Star and Snowflake Schemas
First learning why Reporting is a Problem with a Normalized Schema :
Lets take AdventureWorks2012 sample database . Now The report should include the sales amount for Internet sales in different countries over multiple years. This will end up with almost 10 tables. The AdventureWorks2012 database schema is very normalized; it’s intended as an example schema to support LOB applications.
The goal of normalization is to have a complete and non-redundant schema.
Every piece of information must be stored exactly once. This way, you can enforce data integrity.
So, a query that joins 10 to 12 tables, as would be required in reporting sales by countries
and years, would not be very fast and can cause performance issues as it reads huge amounts of data sales over multiple years and thus would interfere with the regular transactional work of insertion and updation of the data.
Another problem is in many cases, LOB databases are purged otypically after each new fiscal year starts. Even if you have all of the historical data for the sales transactions, you might have a problem showing the historical data correctly. For example, you might have only the latest customer address, which might prevent you from calculating historical sales by country correctly .
The AdventureWorks2012 sample database stores all data in a single database. However, in an enterprise, you might have multiple LOB applications, each of which might store data in its own database. You might also have part of the sales data in one database and part in another.
And you could have customer data in both databases, without a common identification. In such cases, you face the problems of how to merge all this data and how to identify which customer from one database is actually the same as a customer from another database.
Finally, data quality can be low. The old rule, “garbage in garbage out,” applies to analyses as well. Parts of the data could be missing; other parts could be wrong. Even with good data, you could still have different representations of the same data in different databases. For example, gender in one database could be represented with the letters F and M, and in another database with the numbers 1 and 2. So we can put a proper standard in our data warehouse to this problem.
Star Schema
In Figure below, you can easily identify how the Star schema as it resembles
a star. There is a single central table, called a fact table, surrounded by multiple tables called dimensions. One Star schema covers a particular business area. In this case, the schema covers Internet sales. An enterprise data warehouse covers multiple business areas and consists of multiple Star and Snowflake schemas.
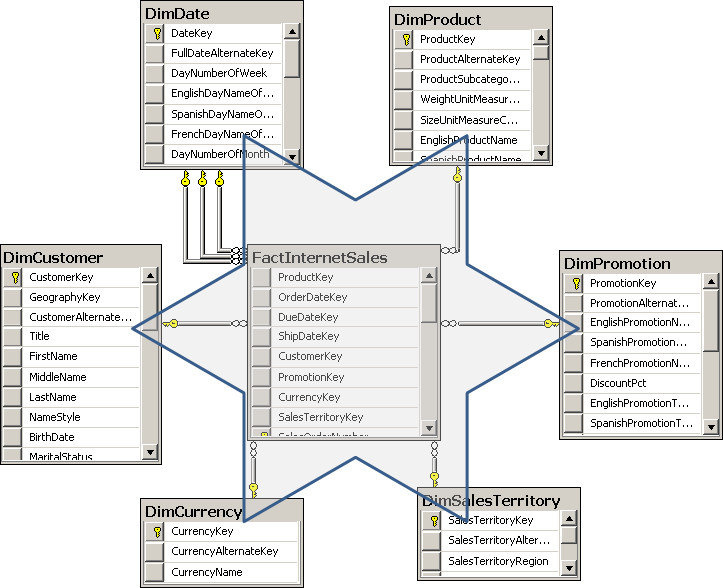
The fact table is connected to all the dimensions with foreign keys. Usually, all foreign keys taken together uniquely identify each row in the fact table, and thus they all together form a unique key, so you can use all the foreign keys as a composite primary key of the fact table. The fact table is on the “many” side of its relationships with the dimensions. If you were to form a proposition from a row in a fact table, you might express it with a sentence such as, “Customer CC purchased product BB on date DD in quantity QQ for amount SS.” .
As we know, a data warehouse consists of multiple Star schemas. From a business perspective, these Star schemas are connected. For example, you have the same customers in sales as in accounting. You deal with many of the same products in sales, inventory, and production. Of course, your business is performed at the same time over all the different business areas. To represent the business correctly, you must be able to connect the multiple Star schemas in your data warehouse. The connection is simple – you use the same dimensions for each Star schema. In fact, the dimensions should be shared among multiple Star schemas. Dimensions have foreign key relationships with multiple fact tables. Dimensions which have connections to multiple fact tables are called shared or conformed dimensions.

Snowflake Schema
You can imagine multiple dimensions designed in a similar normalized way, with a central fact table connected by foreign keys to dimension tables, which are connected with foreign keys to lookup tables, which are connected with foreign keys to their second-level lookup tables.
In this configuration, a star starts to resemble a snowflake. Therefore, a Star schema with normalized dimensions is called a Snowflake schema.
In most long-term projects, you should design Star schemas. Because the Star schema is
simpler than a Snowflake schema, it is also easier to maintain. Queries on a Star schema are simpler and faster than queries on a Snowflake schema, because they involve fewer joins.
Hybrid Schema
In some cases, you can also employ a hybrid approach, using a Snowflake schema only for the first level of a dimension lookup table. In this type of approach, there are no additional levels of lookup tables; the first-level lookup table is denormalized. Figure 1-6 shows such a partially denormalized schema.
Quick Question :
How do we connect multiple star schemas ?
Answer :
Through shared dimensions .
Granularity Level
The number of dimensions connected with a fact table defines the granularity level.
Auditing and Lineage
A data warehouse may also contain auditing tables. For every update, you should audit who and when the update was done and by whom and how many rows were affected to each dimension and fact table in your DW. If you also audit how much time was needed for each load, you can calculate the performance and take action if it slows down. You store this information in an auditing table .
You might also need to know where each row in a dimension and/or fact table came from and when it was added. In such cases, you must add appropriate columns to the dimension and fact tables. Such fine detailed auditing information is also called lineage.
