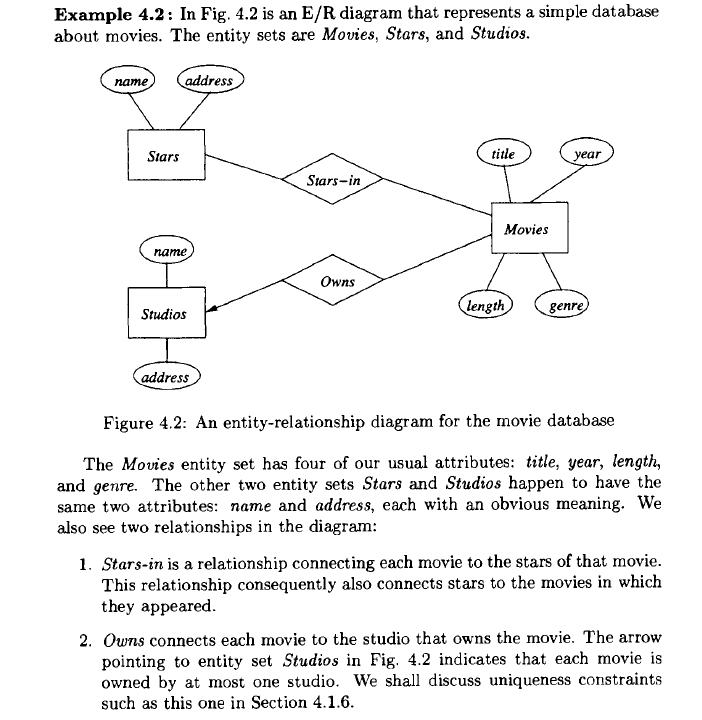
Q 1 : What are types of system databases:
The following are the types of databases:
■ Master database holds instance-wide metadata information, server configuration, information about all databases in the instance, and initialization information. the system views contain information about system, hardware, indexes, columns , memory etc.
■ tempdb The tempdb database is where SQL Server stores temporary data such as work tables, sort space, row versioning information, and so on. SQL Server allows you to create temporary tables for your own use, and the physical location of those temporary tables is tempdb .
■ Resource The Resource database is a hidden, read-only database that holds the definitions of all system objects. When you query system objects in a database, they appear to reside in the sys schema of the local database, but in actuality their definitions reside in the Resource database. contains information that was
previously in the master database and was split out from the master database to make service pack upgrades easier to install.
■ Model The model database is used as a template for new databases. Every new database that you create is initially created as a copy of model. So if you want certain objects (such as data types) to appear in all new databases that you create, or certain database properties to be configured in a certain way in all new databases, you need to create those objects and configure those properties in the model database. Note that changes you apply to the model database will not affect existing databases . The contains information that was previously in the master database and was split out from the master database to make service pack upgrades easier to install.
■ msdb The msdb database is where a service called SQL Server Agent stores its data. SQL Server Agent is in charge of automation, which includes entities such as jobs, schedules, and alerts. The SQL Server Agent is also the service in charge of replication. The msdb database also holds information related to other SQL Server features such as Database Mail, Service Broker, backups, and more.
Q 2 : What is a Filegroup ?
The database is made up of data files and transaction log files . The data files hold object data, and the log files hold information that SQL Server needs to maintain transactions. Data files are organized in logical groups called filegroups.
A filegroup is the target for creating an object, such as a table or an index. The object data will be spread across the files that belong to the target filegroup. Filegroups are your way of controlling the physical locations of your objects.
A database must have at least one filegroup called PRIMARY, and can optionally have other user filegroups as well. The PRIMARY filegroup contains the primary data file (which has an .mdf extension) for the database, and the database’s system catalog. You can optionally add secondary data files (which have an .ndf extension) to PRIMARY. User filegroups contain only secondary data files. You can decide which filegroup is marked as the default filegroup.
This technique can support two main strategies:
■ Using multiple filegroups can increase performance by separating heavily used tables or indexes onto different disk subsystems.
■ Using multiple filegroups can organize the backup and recovery plan by containing static data in one filegroup and more active data in another filegroup. We can allocate or spread filegroups nd1,nd2…ndn to multiple drives to increase performance.
Q 3 : What is a Primary key?
A primary key constraint enforces uniqueness of rows and also disallows NULL marks in the constraint attributes.
Q 4 : What is a Unique Constraints ?
A unique constraint enforces the uniqueness of rows, allowing you to implement the concept of alternate keys from the relational model in your database. Unlike with primary keys, you can define multiple unique constraints within the same table. Also, a unique constraint is not restricted to columns defined as NOT NULL.
Q 5 : What is a Foreign Key Constraints ?
A foreign key enforces referential integrity. This constraint is defined on one or more attributes in what’s called the referencing table and points to candidate key (primary key or unique constraint) attributes in what’s called the referenced table . Note that NULL marks are allowed in the foreign key columns (mgrid in the last example) even if
there are no NULL marks in the referenced candidate key columns.
Q 6 : What is a Check Constraints ?
A check constraint allows you to define a predicate that a row must meet to be entered into the table or to be modified. For example, the following check constraint ensures that the salary column in the Employees table will support only positive values.
ALTER TABLE dbo.Employees
ADD CONSTRAINT CHK_Employees_salary
CHECK(salary > 0.00);
Q 7 : What is the difference between where and having clause ?
The WHERE clause is evaluated before rows are grouped, and therefore is evaluated
per row. The HAVING clause is evaluated after rows are grouped, and therefore
is evaluated per group.
Q 8 : Why it is not allowed to refer to a column alias defined by the SELECT
clause in the WHERE clause?
Because the WHERE clause is logically evaluated first in query processing than the SELECT clause.
Q 9 : What is the performance wise benefits of the WHERE clause ?
It reduces network traffic and if properly used with indexes can reduce the full table scanning.
Q 10 : What is the difference between self-contained and correlated subqueries?
Self-contained sub queries are independent of the outer query, whereas correlated
sub queries have a reference to an element from the table in the outer query.
Q 11 : What is the difference between the APPLY and JOIN operators?
With a JOIN operator, both inputs represent static relations. With APPLY, the
left side is a static relation, but the right side can be a table expression with
correlations to elements from the left table.
Q 12 : What are two requirements for the queries involved in a set operator ?
The number of columns in the two queries needs to be the same and the corresponding
columns need to have compatible types.
Q 13 : What makes a query a grouped query?
When you use an aggregate function, a GROUP BY clause, or both.
Q 14 : What are the clauses that you can use to define multiple grouping sets in the
same query?
GROUPING SETS, CUBE, and ROLLUP.
Q 15 : What is the difference between PIVOT and UNPIVOT?
PIVOT rotates data from a state of rows to a state of columns; UNPIVOT rotates
the data from columns to rows.
Q 16 : Can you store indexes from the same full-text catalog to different filegroups?
Yes. A full-text catalog is a virtual object only; full-text indexes are physical objects.
You can store each full-text index from the same catalog to a different file group.
Q 17 : How do you search for synonyms of a word with the CONTAINS predicate?
You have to use the CONTAINS(FTcolumn, ‘FORMSOF(THESAURUS, SearchWord1)’) syntax.
Q 18 : Can a table or column name contain spaces, apostrophes, and other nonstandard characters?
Yes
Q 19 : What types of table compression are available?
Page and row level compression.
Q 20 : How SQL Server enforce uniqueness in both primary key and unique constraints?
SQL Server uses unique indexes to enforce uniqueness for both primary key
and unique constraints.
Q 21 : What type of data does an inline function return?
Inline functions return tables, and accordingly, are often referred to as inline
table-valued functions.
Q 22 : What is difference between view and an inline function ?
An inline table-valued function can be said as a parameterized view—that is, a
view that takes parameters.
Q 23 : What is the difference between SELECT INTO and INSERT SELECT?
SELECT INTO creates the target table and inserts into it the result of the query.
INSERT SELECT inserts the result of the query into an already existing table.
Q 24: Can we update rows in more than one table in one UPDATE statement?
No, we can use columns from multiple tables as the source, but update only
one table at a time.
Q 25 : How many columns with an IDENTITY property are supported in one table? And How do you obtain a new value from a sequence?
One.
We use NEXT VALUE FOR function for it.
Q 26 : What is the purpose of the ON clause in the MERGE statement?
The ON clause determines whether a source row is matched by a target row,
and whether a target row is matched by a source row. Based on the result of
the predicate, the MERGE statement knows which WHEN clause to activate and
as a result, which action to take against the target.
Q 27 : What are the possible actions in the WHEN MATCHED clause?
UPDATE and DELETE.
Q 28 : How many WHEN MATCHED clauses can a single MERGE statement have?
Two—one with an UPDATE action and one with a DELETE action.
Q 29: Why is it important for SQL Server to maintain the ACID quality of
transactions?
To ensure that the integrity of database data will not be compromised.
Q 30 : How does SQL Server implement transaction durability?
By first writing all changes to the database transaction log before making changes permanently to the database data on disk.
Q 31 : How many ROLLBACKs must be executed in a nested transaction to roll it back?
Only one ROLLBACK. A ROLLBACK always rolls back the entire transaction, no
matter how many levels the transaction has.
Q 32 : How many COMMITs must be executed in a nested transaction to ensure that
the entire transaction is committed?
One COMMIT for each level of the nested transaction. Only the last COMMIT
actually commits the entire transaction.
Q 33 : Can readers block readers?
No because shared locks are compatible with other shared locks.
Q 34: Can readers block writers?
Yes, even if only momentarily, because any exclusive lock request has to wait
until the shared lock is released.
Q 35 : If two transactions never block each other, can a deadlock between them
result?
No. In order to deadlock, each transaction must already have locked a resource the other transaction wants, resulting in mutual blocking.
Q 36 : Can a SELECT statement be involved in a deadlock?
Yes. If the SELECT statement locks some resource that keeps a second transaction
from finishing, and the SELECT cannot finish because it is blocked by the
same transaction, the deadlock results.
Q 37 : If your session is in the READ COMMITTED isolation level, is it possible for one of your queries to read uncommitted data?
Yes, if the query uses the WITH (NOLOCK) or WITH (READUNCOMMITTED)
table hint where WITH (NOLOCK) ignoring the locks . The session value for the isolation level does not change, just the characteristics for reading that table.
Q 38 : Is there a way to prevent readers from blocking writers and still ensure that
readers only see committed data?
Yes, that is the purpose of the READ COMMITTED SNAPSHOT option within the
READ COMMITTED isolation level. Readers see earlier versions of data changes
for current transactions, not the currently uncommitted data.
Q 39 : What is the result of the parsing phase of query execution?
The result of this phase, if the query passed the syntax check, is a tree of logical
operators known as a parse tree.
Q 40 : How we measure the amount of disk I/O a query is performing?
We use the SET STATISTICS IO command.
Q 41 : Which DMO gives you detailed text of queries executed?
You can retrieve the text of batches and queries executed from the
sys.dm_exec_sql_text DMO.
Q 42 :What are the two types of parameters for a T-SQL stored procedure?
A T-SQL stored procedure can have only an input and a output parameter.
Q 43 : Can a stored procedure span multiple batches of T-SQL code?
No, a stored procedure can only contain one batch of T-SQL code.
Q 44 : What are the two types of DML triggers that can be created?
You can create AFTER and INSTEAD OF DML-type triggers.
Q 45 : If an AFTER trigger discovers an error, how does it prevent the DML command from completing?
An AFTER trigger issues a THROW or RAISERROR command to cause the transaction
of the DML command to roll back.
Q 46 : What are the two types of table-valued UDFS? And What type of UDF returns only a single value?
You can create inline or multistatement table-valued UDFs. And scalar UDF returns only a single value.
Q 47 : What kind of clustering key would you select for an OLTP environment?
For an OLTP environment, a short, unique, and sequential clustering key might be
the best choice.
Q 48 : Which clauses of a query should you consider supporting with an index?
The list of the clauses you should consider supporting with an index includes, but
is not limited to, the WHERE, JOIN, GROUP BY, and ORDER BY clauses.
Q 49 : How would you quickly update statistics for the whole database after an upgrade?
We should use the sys.sp_updatestats system procedure .
Q 50 : What are the commands that are required to work with a cursor?
DECLARE, OPEN, FETCH in a loop, CLOSE, and DEALLOCATE.
Q 51 : When using the FAST_FORWARD option in the cursor declaration command,
what does it mean regarding the cursor properties?
It means that the cursor is read-only, forward-only.
Q 52 : How would you determine whether SQL Server used the batch processing mode for a specific iterator?
You can check the iterator’s Actual Execution Mode property.
Q 53 : Would you prefer using plan guides instead of optimizer hints?
With plan guides, you do not need to change the query text.
Q 54 : Why relational model is called set based model ?
Relational model means that it is based on the concepts of mathematical set theory. SQL queries that query on the SQL tables outputs the rows in the form of sets of rows.
Q 55 : Give example of iterative model?
Iterative model means the same concept which is used in loop iteration in high level languages such as C or python . In the same way , the iterative model works on rows as they go row by row. They are by comparison slower in performance .Example : Cursors.
Q 56 : What does fast forward cursor means ?
Means that cursor will start from the initiating point to the last element and will not go backward.
Q 57 : What are scopes of temporary tables ?
There are two types of temporary tables in SQL : local and global.
Local temp tables are visible to the level that created , across the all inner batches and to the all inner levels of call stack.
Global temp tables are where destroyed when the session that created it terminates or destroyed.
Table variables are named with @ sign : @TV1. They are only accessible to batch that created it .They are not visible to across batches at same level and not even to inner levels .
Q 58: What is the difference between temp table and table variable?
Temp tables are similar to regular database tables . Any data changes in temp tables during transaction can be rolled back . But changes in table variable in a transaction can not be rolled back.
Another difference is performance wise , for temp tables SQL maintains histograms . Means we can see their statistics and work on them to improve performance for instance : we can create indexes on columns for filtering out the data properly.
In case of table variables , it performs the full table scan which decreases the performance.
Q 59 : What does SET NOCOUNT ON do ?
NOCOUNT ON can remove the messages like : 2 rows affected returned .Putting
a SET NOCOUNT ON at the beginning of stored procedure prevents from returning that message to the client.
Q 60 : What does GOTO statement does ?
With GOTO you can jump to the particular label to from where you are at!
For instance :
PRINT ‘First’;
GOTO Label_1;
PRINT ‘Second’;
Label_1:
PRINT ‘End now’;
Q 61 : Can the stored procedure have multiple batches ?
No.
Q 62 : What does RETURN statement do ?
It exits the stored procedure and returns to caller statement or procedure .
Q 63: What does @@Rowcount does?
It counts the number of rows read or affected by the SQL statement .
Q 64: Can the AFTER triggers be nested ?
Yes they can be nested , means that trigger on a table T1 can have a trigger and that inserts rows into table T2 that is also having a trigger on it and so on .
The number of maximum nested triggers SQL can have is 32.
Q 65 : What does SCHEMABINDING statement do?
WITH SCHEMABINDING means that a schema object is dependent or have a some sort of bound with other object . Object can be a table ,view or procedure. For instance : You cannot change the table structure if it is schemabinded with another view until you drop that view.
Q 66 : Can we use multiple select statements in a view ?
No . Only you can use one select statement as it is required that a view returns one result set.
But , you can use union statement with two or more select statements as the final result would be one result set.
Q 67 : Can data be modified in a table with a view ? If yes then what precautions are there?
Yes we can modify data in a table through a view instead of directly modifying through the table.
There are few precautions and restriction that should be taken carefully :
- The DML statement must use or point to one table only even if the view is made up of or referencing multiple tables.
- The view column to be modified should not have a aggregate function on it in the table or a view whose column is resulted from GROUP BY , DISTINCT or HAVING .
- We cannot modify a view if it is having TOP or offset fetch with the WITH CHECK OPTION.
- The data in the view column cannot be modified if it is made up from Union, union All , intersect or cross joins.
Q 68 : What are partitioned views?
We can partition large table in SQL with help of views on one or across several servers. Simply you can use union on partitioned tables and create a view for it. It is called partitioned view. If the table is spread across multiple SQL instances then it is called distributed partitioned view.
Q 69 : What is inline table valued function ?
It is also a type of view called parameterized view . The difference is that only it can take parameter to filter the rows from the view.
Q 70 : What is identity?
It is a type of property for a column having a type numeric. We typically use the identity column to generate surrogate keys which are mostly generated by system automatically when you insert the data. It has two values in it . First is seed value which is the first value and second is step value which is incremental value. We define both of these values at definition.
Q 71 : What is SET IDENTITY_INSERT?
We can specify our own values for identity column for insert by SET IDENTITY_INSERT = ON . But we cannot update identity column value.
Q 72 : How can we find last Identity value?
The SCOPE_IDENTITY returns last identity value which is generated in the session in the current scope (batch, procedure or function) .
The @@IDENTITY returns the last identity value generated in the session inspite what is the scope.
The IDENT_CURRENT takes table as input and returns the last identity value being generated in the given table .
Q 73 : What will happen if we use Scope_Identity , @@Identity and Ident_current in different sessions?
Scope_Identity and @@Identity will return NULL but Ident_current will return the last value of the identity column whatever the session is.
Q 74 : What is sequence ?
Sequence is an independent object in SQL Server . It is quite like the identity column .
All numeric types are accepted by sequence as like the identity does. But By default is BIGINT.
There are number of properties which identity does not have :
■ INCREMENT BY : It Increments the value. The default value is 1.
■ MINVALUE : The minimum value for the type .
■ MAXVALUE :The maximum value to be given for the type .
■ CYCLE | NO CYCLE : It deals if to allow the sequence to cycle or not. The default value is NO CYCLE.
■ START WITH : It is the sequence start value.
Q 75 : How can we request next Value in sequence ?
To request new value from the sequence, run the following code .
SELECT NEXT VALUE FOR tableName;
Q 76 : Can we change the datatype of sequence ? And can we change properties and values ?
No we cannot change the datatype but yes we can change properties and values.
Q 77 : What is cache in sequence ?
This property means writing the sequence value to disk . For instance a CACHE with value 100 means it will write to disk after every 100 . Performance wise using NO CACHE has to write to disk each request of new sequence value. With CACHING performance is good.
Q78 : What is APPLY operator ?
The APPLY operator works on two input tables in which the second can be a table expression.
And we will refer to them as the “left” and “right” tables and the right table is usually a derived table or an inline table valued function.
The APPLY operator applies the right table expression to each row from the left table and produces a result table with the unified result sets.
We will discuss this in separate post.
Q78 : What is the difference between Cross and outer apply?
The APPLY operator has two types;
CROSS APPLY doesn’t return left rows that get an empty set back from the right side.
The OUTER APPLY preserves the left side, and therefore, does return left rows when the right side returns an empty set. NULLs are used as placeholders from the right side in the outer rows if they are empty.
Q79 : What is Transaction ?
Transaction is a unit of work that has many activities like querying a data and changing multiple data definition statement or queries.
Q80 : What is implicit_transactions? Statement ?
This statement is OFF by default in SQL . If you do not start your transaction with BEGIN statement it is fine but you have to specify COMMIT OR ROLLBACK TRAN to end the transaction.
Q 81 : Define 4 properties of a transaction ?
Atomicity: Either all changes in the transaction takes place or None. If a system fails before a COMMIT in a transaction or there is an error , the transaction is being rolled back.
Consistency : It is the state of data the database gives access to the user .The isolation level is also a part of consistency. Consistency also refers to the integrity rules it follows like (Primary Key , Foreign Key and Unique constraints ) etc .
Isolation : Isolation level means to handle and control the access level of data and ensure data is in the level of consistency . There are two types of isolation levels : Locking and row versioning .
Durability : It means that the data is durable . Whenever , the data is changed it is first logged into the Logs of the database before it can be written to disk . Once the data is Committed and written to logs it is considered safe even the system fails.
Q 82 : What is redo and undo ?
If the system fails , when it gets started it checks the logs and replays the data and checks for committed data , if its committed it rolls forward and Redo .
If the data is uncommitted it gets rolled back to previous state once the system is up .
Q 83 : What is a lock ?
Lock is a control resource obtained by the transaction to protect data and prevent data changes or access by another transaction .
Q 84 : What is an Exclusive Lock ?
When we want to modify a data , the transaction requests an exclusive lock on the data and its resources. If it acquires the exclusive lock it will not allow any other transaction to access or modify data until that transaction releases the lock .
In single statement transaction , the lock is held until the statement completes.
In multi statement transaction , the lock is held until all the statements are executed and the transaction is ended by Commit tran or rollback Tran.
If a transaction is holding any type of lock on a resource then it can not acquire Exclusive lock and no lock can acquire any resource if a transaction is having an Exclusive lock.
Q 85 : What is shared lock ?
When a transaction reads a data , the transaction acquires Shared lock on it and its resources . Multiple transactions can acquire shared locks simultaneously on a same resource.
Q 86 : What is row versioning ? What is READ COMMITTED SNAPSHOT Isolation level ?
In Azure SQL database Read Committed Snapshot is the default isolation level.
Instead of Locking technology , this isolation level works on row versioning , so the transaction does not wait for acquiring shared lock for reading .
In this READ COMMITTED SNAPSHOT isolation level , if the transaction modifies a row and another transaction tries to read the row , it will read the last committed state of the row that was available before the start of the statement (optimistic Concurrency) .
This case is very different in READ COMMITTED isolation level , if the transaction is modifying the row , another transaction cannot read the same rows of data until the first transaction completes (Pessimistic Concurrency ) .
Q 87 : What are lockable resources ?
Lockable resources are : RID, rows , tables , pages and database tables.
Q 88 : What is higher level of Granularity ?
To obtain lock on a resource , your transaction must first obtain intent locks of the same mode on higher levels of granularity . For example, to get an exclusive lock on a row, your transaction must first acquire an intent exclusive lock on the page where the row resides and an intent exclusive lock on the object that owns the page.
To get a shared lock on a certain level of granularity, your transaction first needs to acquire intent shared locks on higher levels of granularity.
The purpose of intent locks is to efficiently detect incompatible lock requests on higher levels of granularity and prevent the granting of those.
For instance , if a transaction holds a lock on a row and another asks for an incompatible lock mode on the whole page(higher level) or table where that row resides, it is easy for SQL Server to identify the conflict because of the intent locks that the first transaction acquired on the page and table. Intent locks do not interfere with requests for locks on lower levels of granularity. For example, an intent lock on a page doesn’t prevent other transactions from acquiring incompatible lock modes on rows within the page.
Q 89 : What is Blocking ?
When one transaction holds a data resource and another requests for the same resource , so requester gets blocked and enters into the wait state.
Q 90 : What is isolation level READ UNCOMMITTED ?
It the lowest available isolation level. In this isolation level, a reader doesn’t
ask for a shared lock. A reader that doesn’t ask for a shared lock can never be in conflict with a writer that is holding an exclusive lock. This means that the reader can read uncommitted changes (also known as dirty reads). It also means that the reader won’t interfere with a writer that asks for an exclusive lock. In other words, a writer can change data while a reader that is running under the READ UNCOMMITTED isolation level reads data.
Q 91 : What is the isolation level READ COMMITED ?
It does not allow dirty reads or uncommitted data . It allows the reader to acquire shared lock to prevent reading the uncommitted data.
This means that if a writer is holding an exclusive lock, the reader’s shared lock request will be in conflict with the writer, and it has to wait.
As soon as the writer commits the transaction, the reader can get its shared lock, but what it reads are necessarily only committed changes.
Q 92 : What is the isolation level REPEATABLE READ ?
It not only does a reader need a shared lock to be able to read, but it also holds the lock until the end of the transaction. This means that as soon as the reader has acquired a shared lock on a data resource to read it, no one can obtain an exclusive lock to modify that resource until the reader ends the transaction.
If a transaction is having a shared lock and it is not committed and it is in repeatable read isolation level, then it will not allow any other transaction to update the data of the first transaction until the first transaction is not committed.
Q 93 : What is isolation level SERIALIZABLE ?
One problem in REPEATABLE READ is that what if a another transaction enters a new row or rows into the table ? this phenomenon is called Phantom Reads . To overcome this problem , we use the SERIALIZABLE . It blocks the other transaction to enter the new rows.